개발세발보안중
ARX Anonymization Tool 본문
개인정보 비식별화
비식별화는, 데이터 내에 개인을 식별할 수 있는 정보가 있는 경우, 이의 일부 또는 전부를 삭제, 또는 일부를 속성 정보로 대체 처리함으로써 다른 정보와 결합하여도 특정 개인을 식별하기 어렵도록 하는 조치입니다.
비식별화에서 가장 기본적인 기법은 k-익명성입니다.
k-익명성이란, 특정인임을 추론할 수 있는지 여부를 검토하고, 일정 확률수준 이상으로 비식별 되도록 하는 것입니다.
예를 들어, 동일한 값을 가진 레코드를 k개 이상으로 하면, 특정 개인을 식별할 확률이 1/k가 됩니다.
민감 정보가 포함된다면 l-다양성, t-근접성의 방법을 고려합니다.
l-다양성은 특정인 추론이 안된다고 해도 민감한 정보의 다양성을 높여 추론 가능성을 낮추는 기법입니다.
t-근접성은 전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t이하로 하여 추론을 방지하는 기법입니다.
ARX는 비식별화를 수행하는 오픈소스 프로그램입니다.
arx.deidentifier.org
ARX - Data Anonymization Tool | A comprehensive software for privacy-preserving microdata publishing
Holistic Approach ARX is not just a tool box, but a fully fledged application. All methods have been carefully selected and tightly integrated with each other. ARX provides compatibility with SQL databases, MS Excel and CSV files. Moreover, it supports dat
arx.deidentifier.org
ARX 비식별화 프로세스는 세가지 단계로 구성되어 있습니다.

첫 단계는 Raw Data를 Import하여 데이터 변환모형과 프라이버시 모형을 설정하는 Configure 단계이고
두 번째 단계는 설정된 모형을 만족하는 모든 가능한 변환을 도식화하여 보여주는 Explore 기능입니다.
Explor 단계에서 적절한 변환모형을 선택하면 세 번째 단계인 Analyze 단계로 넘어갑니다.
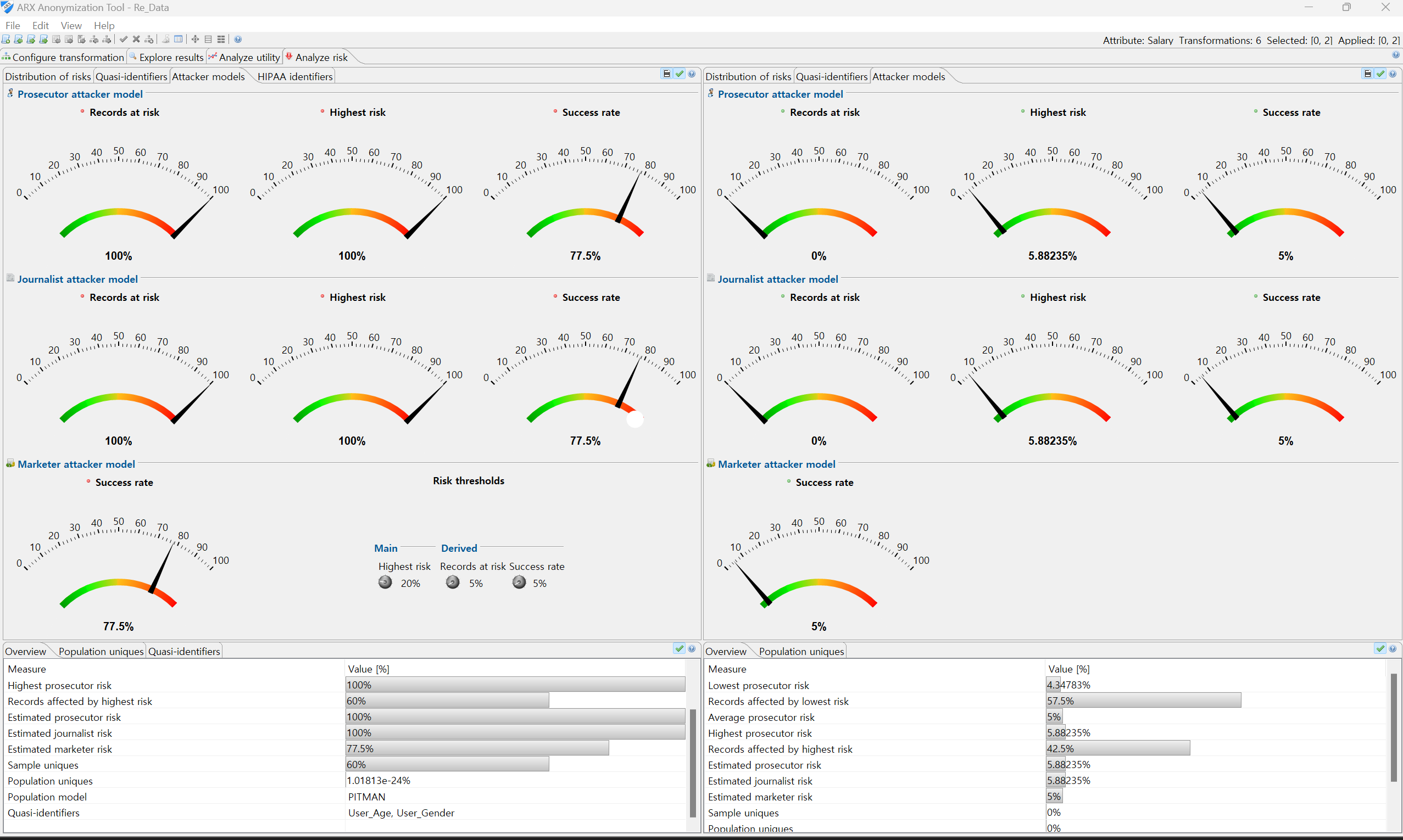
이 때 재식별화가능성 등 위험수준을 분석하여 최종 Export 여부를 결정합니다.

1. 나이 인터벌


-----------------------------다시...----------------------------------------------------






비밀번호 제외 모든 데이터에 대해서 마스킹, 오더링, 인터벌 설정했습니다.
이제 프라이버시 모델을 추가하겠습니다.



k : 7
l : 2(장애여부), 5(연봉) 이렇게 설정한 결과 ~